Welcome! Meet our Python Code Assistant, your new coding buddy. Why wait? Start exploring now!
Finding subdomains of a particular website lets you explore its full domain infrastructure of it. Building such a tool is really handy in the information gathering phase in penetration testing for ethical hackers.
Searching for subdomains manually would take forever. Luckily, we don't have to do that. In this tutorial, we will build a subdomain scanner in Python using the requests library. Let's get started!
Related: How to Use Shodan API in Python.
Let's install it:
pip3 install requestsThe method we gonna use here is brute-forcing. In other words, we gonna test all common subdomain names of that particular domain. Whenever we receive a response from the server, that's an indicator for us that the subdomain is alive.
Open up a new Python file and follow along. Let's use google.com for demonstration purposes; and I used it because google has a lot of subdomains, though:
import requests
# the domain to scan for subdomains
domain = "google.com"Get: Build 24 Ethical Hacking Scripts & Tools with Python Book
Now we gonna need a big list of subdomains to scan, I've used a list of 100 subdomains just for demonstration, but in the real world, if you really want to discover all subdomains, you gotta use a bigger list. Check this GitHub repository which contains up to 10K subdomains.
I have a file "subdomains.txt" in the current directory. Make sure you do, too (grab the list of your choice in this repository):
# read all subdomains
file = open("subdomains.txt")
# read all content
content = file.read()
# split by new lines
subdomains = content.splitlines()Now subdomains list contains the subdomains we want to test. Let's brute-force:
# a list of discovered subdomains
discovered_subdomains = []
for subdomain in subdomains:
# construct the url
url = f"http://{subdomain}.{domain}"
try:
# if this raises an ERROR, that means the subdomain does not exist
requests.get(url)
except requests.ConnectionError:
# if the subdomain does not exist, just pass, print nothing
pass
else:
print("[+] Discovered subdomain:", url)
# append the discovered subdomain to our list
discovered_subdomains.append(url)First, we build up the URL to be suitable for sending a request, and then we use requests.get() function to get the HTTP response from the server. This will raise a ConnectionError exception whenever a server does not respond; that's why we wrapped it in a try/except block.
When the exception wasn't raised, then the subdomain exists. Let's write all the discovered subdomains to a file:
# save the discovered subdomains into a file
with open("discovered_subdomains.txt", "w") as f:
for subdomain in discovered_subdomains:
print(subdomain, file=f)Here is a part of the result when I ran the script:
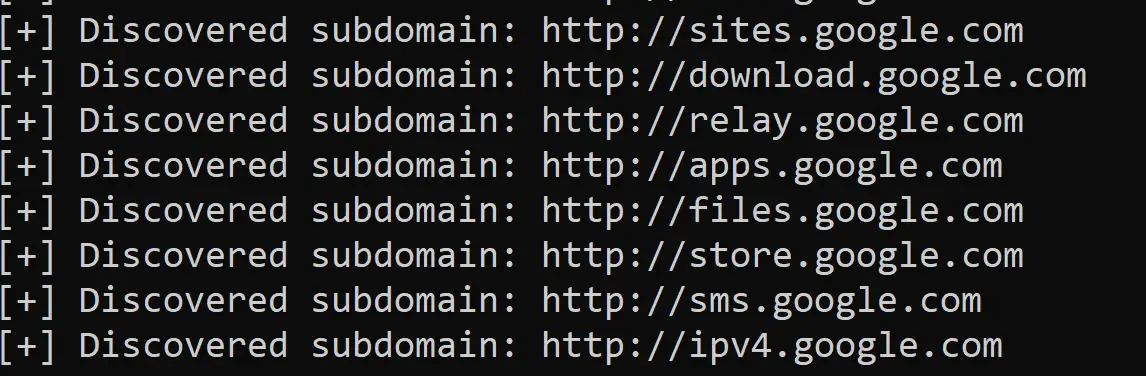
Once it's finished, you'll see a new file discovered_subdomains.txt appears, which includes all the discovered subdomains!
You'll notice when you run the script that's quite slow, especially when you use longer lists, as it's using a single thread to scan. However, if you want to accelerate the scanning process, you can use multiple threads for scanning. I've already written one. Check it here.
Alright, we are done. Now you know how to discover subdomains of any website you want!
Finally, In our Ethical Hacking with Python Ebook, we built 24 hacking tools from scratch using Python. Make sure to check it out here if you're interested!
Read Also: How to Get Domain Name Information in Python.
Happy Scanning ♥
Want to code smarter? Our Python Code Assistant is waiting to help you. Try it now!
View Full Code Create Code for Me



Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!