Get a head start on your coding projects with our Python Code Generator. Perfect for those times when you need a quick solution. Don't wait, try it today!
Do you want to export tables from PDF files with Python programming language? You're in the right place.
Camelot is a Python library and a command-line tool that makes it easy for anyone to extract data tables trapped inside PDF files. Check their official documentation and GitHub repository.
Whereas Tabula-py is a simple Python wrapper of tabula-java, which can read tables in a PDF. It lets you convert a PDF file into a CSV, TSV, JSON, or even a pandas DataFrame. Make sure to have JRE installed in your operating system if you want to use Tabula-py.
In this tutorial, you will learn how to extract tables in PDF using both Camelot and tabula-py libraries in Python.
Download: Practical Python PDF Processing EBook.
First, you need to install the required dependencies for the Camelot library to work properly, and then you can install the libraries using the command line:
pip3 install camelot-py[cv] tabula-pyNote that you need to make sure that you have Tkinter and ghostscript (which are the required dependencies for Camelot) installed properly on your computer.
Extracting PDF Tables using Camelot
Now that you have installed all requirements for this tutorial, open up a new Python file and follow along:
import camelot
# PDF file to extract tables from
file = "foo.pdf"I have a PDF file in the current directory called "foo.pdf" (get it here) which is a standard PDF page that contains one table shown in the following image:
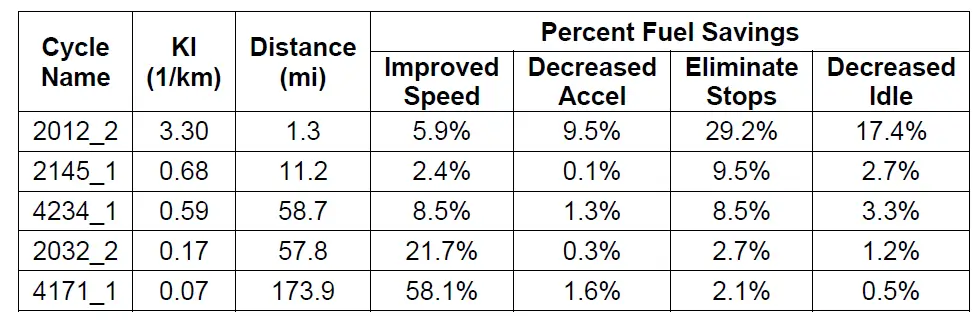
Just a random table. Let's extract it in Python:
# extract all the tables in the PDF file
tables = camelot.read_pdf(file)read_pdf() function extracts all tables in a PDF file. Let's print the number of tables extracted:
# number of tables extracted
print("Total tables extracted:", tables.n)This outputs:
Total tables extracted: 1 Sure enough, it contains only one table, printing this table as a Pandas DataFrame:
# print the first table as Pandas DataFrame
print(tables[0].df)Output:
0 1 2 3 4 5 6
0 Cycle \nName KI \n(1/km) Distance \n(mi) Percent Fuel Savings
1 Improved \nSpeed Decreased \nAccel Eliminate \nStops Decreased \nIdle
2 2012_2 3.30 1.3 5.9% 9.5% 29.2% 17.4%
3 2145_1 0.68 11.2 2.4% 0.1% 9.5% 2.7%
4 4234_1 0.59 58.7 8.5% 1.3% 8.5% 3.3%
5 2032_2 0.17 57.8 21.7% 0.3% 2.7% 1.2%
6 4171_1 0.07 173.9 58.1% 1.6% 2.1% 0.5%That's precise. Let's export the table to a CSV file:
# export individually as CSV
tables[0].to_csv("foo.csv")CSV isn't the only option; you can also use to_excel(), to_html(), to_json() and to_sqlite() methods, here is an example exporting to Excel spreadsheet:
# export individually as Excel (.xlsx extension)
tables[0].to_excel("foo.xlsx")Or if you want to export all tables in one go:
# or export all in a zip
tables.export("foo.csv", f="csv", compress=True)f parameter indicates the file format, in this case, "csv". By setting compress parameter equal to True, this will create a ZIP file that contains all the tables in CSV format.
You can also export the tables to HTML format:
# export to HTML
tables.export("foo.html", f="html")or you can export to other formats such as JSON and Excel too.
It is worth noting that Camelot only works with text-based PDFs and not scanned documents. If you can click and drag to select text in your table in a PDF viewer, it is a text-based PDF, so this will work on papers, books, documents, and much more!
Read also: How to Split PDF Files in Python.
Get Our Practical Python PDF Processing EBook
Master PDF Manipulation with Python by building PDF tools from scratch. Get your copy now!
Download EBookExtracting PDF Tables using Tabula-py
Open up a new Python file and import tabula:
import tabula
import osWe simply use read_pdf() method to extract tables within PDF files (again, get the example PDF here):
# read PDF file
tables = tabula.read_pdf("1710.05006.pdf", pages="all")We set pages to "all" to extract tables in all the PDF pages, the tabula.read_pdf() method returns a list of pandas DataFrames, each DataFrame corresponds to a table. You can also pass a URL to this method and it'll automatically download the PDF before extracting tables.
The below code is an example of iterating over all extracted tables and saving them as Excel spreadsheets:
# save them in a folder
folder_name = "tables"
if not os.path.isdir(folder_name):
os.mkdir(folder_name)
# iterate over extracted tables and export as excel individually
for i, table in enumerate(tables, start=1):
table.to_excel(os.path.join(folder_name, f"table_{i}.xlsx"), index=False)This will create tables folder and put all detected tables in Excel format into that folder, try it out.
Now, what if you want to extract all tables from a PDF file and dump them into a single CSV file? The below code does exactly that:
# convert all tables of a PDF file into a single CSV file
# supported output_formats are "csv", "json" or "tsv"
tabula.convert_into("1710.05006.pdf", "output.csv", output_format="csv", pages="all")If you have multiple PDF files and you want to run the above on all of them, then you can use convert_into_by_batch() method:
# convert all PDFs in a folder into CSV format
# `pdfs` folder should exist in the current directory
tabula.convert_into_by_batch("pdfs", output_format="csv", pages="all")This will look into the pdfs folder and output a CSV file for each PDF file in that folder.
Get Our Practical Python PDF Processing EBook
Master PDF Manipulation with Python by building PDF tools from scratch. Get your copy now!
Download EBookConclusion
For large files, the Camelot library tends to outperform tabula-py. However, sometimes you'll encounter a NotImplementedError for some PDFs using the Camelot library, you can use tabula-py as an alternative.
Note that this won't convert image characters to digital text. If you wish so, you can use OCR techniques to convert image optical characters to the actual text that can be manipulated in Python. The below tutorials can help you:
- Optical Character Recognition (OCR) in Python
- How to Extract Text from Images in PDF Files with Python
Below are some related PDF tutorials that may help you in your work:
For a complete list, check the category's page.
Alright, this is it for this tutorial. Check Camelot's official documentation and tabula-py official documentation for more detailed information.
Finally, we have an entire EBook about PDF Processing with Python, and there is a section where we dive deeper into extracting tables using Camelot, Tabula-Py, and PDFPlumber. Check it out here if you're interested.
Check the complete code here.
Happy Coding ♥
Want to code smarter? Our Python Code Assistant is waiting to help you. Try it now!
View Full Code Generate Python Code



Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!