Get a head start on your coding projects with our Python Code Generator. Perfect for those times when you need a quick solution. Don't wait, try it today!
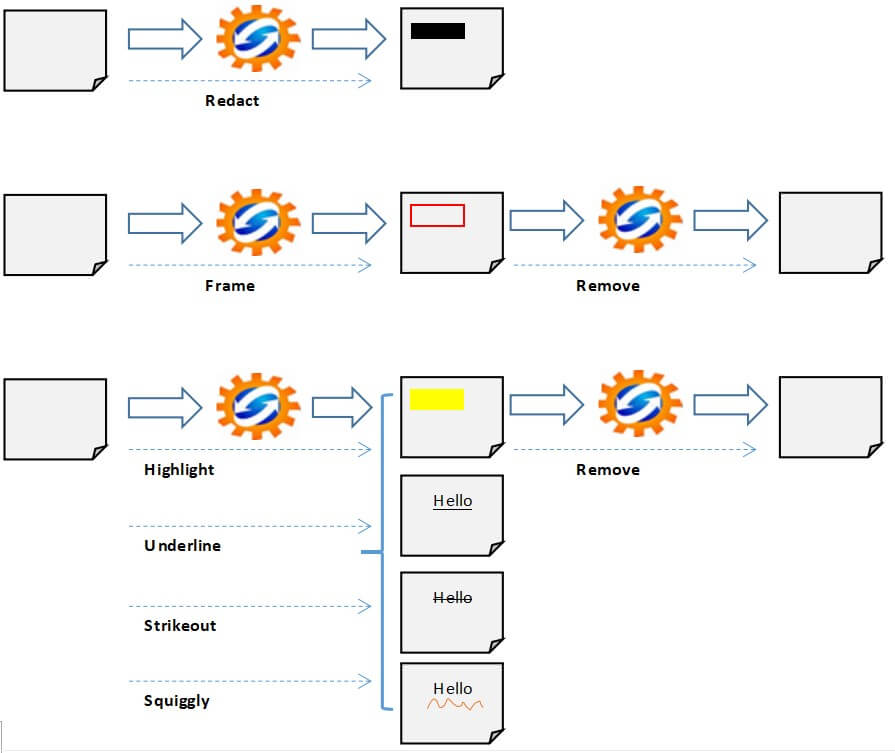
Highlighting or annotating a text in a PDF file is a great strategy for reading and retaining key information. This technique can help in bringing important information immediately to the reader's attention. There is no doubt that a text highlighted in yellow would probably catch your eye first.
Redacting a PDF file allows you to hide sensitive information while keeping your document's formatting. This preserves private and confidential information before sharing. Moreover, it further boosts the organization's integrity and credibility in handling sensitive information.
Get: Practical Python PDF Processing EBook.
In this tutorial, you will learn how to redact, frame, or highlight text in PDF files using Python.
In this guide, we'll be using the PyMuPDF library, which is a highly versatile, customizable PDF, XPS, and EBook interpreter solution that can be used across a wide range of applications as a PDF renderer, viewer, or toolkit.
The goal of this tutorial is to develop a lightweight command-line-based utility to redact, frame, or highlight a text included in one PDF file or within a folder containing a collection of PDF files. Moreover, it will enable you to remove the highlights from a PDF file or a collection of PDF files.
Let's install the requirements:
$ pip install PyMuPDF==1.18.9Open up a new Python file, and let's get started:
# Import Libraries
from typing import Tuple
from io import BytesIO
import os
import argparse
import re
import fitz
def extract_info(input_file: str):
"""
Extracts file info
"""
# Open the PDF
pdfDoc = fitz.open(input_file)
output = {
"File": input_file, "Encrypted": ("True" if pdfDoc.isEncrypted else "False")
}
# If PDF is encrypted the file metadata cannot be extracted
if not pdfDoc.isEncrypted:
for key, value in pdfDoc.metadata.items():
output[key] = value
# To Display File Info
print("## File Information ##################################################")
print("\n".join("{}:{}".format(i, j) for i, j in output.items()))
print("######################################################################")
return True, outputGet Our Practical Python PDF Processing EBook
Master PDF Manipulation with Python by building PDF tools from scratch. Get your copy now!
Download EBookThe extract_info() function collects the metadata of a PDF file, the attributes that can be extracted are format, title, author, subject, keywords, creator, producer, creation date, modification date, trapped, encryption, and the number of pages. It is worth noting that these attributes cannot be extracted when you target an encrypted PDF file.
def search_for_text(lines, search_str):
"""
Search for the search string within the document lines
"""
for line in lines:
# Find all matches within one line
results = re.findall(search_str, line, re.IGNORECASE)
# In case multiple matches within one line
for result in results:
yield resultThis function searches for a string within the document lines using the re.findall() function, re.IGNORECASE is to ignore the case while searching.
def redact_matching_data(page, matched_values):
"""
Redacts matching values
"""
matches_found = 0
# Loop throughout matching values
for val in matched_values:
matches_found += 1
matching_val_area = page.searchFor(val)
# Redact matching values
[page.addRedactAnnot(area, text=" ", fill=(0, 0, 0))
for area in matching_val_area]
# Apply the redaction
page.apply_redactions()
return matches_foundThis function performs the following:
- Loop throughout the matching values of the search string we are searching for.
- Redact the matching values.
- Apply the redaction on the selected page.
You can change the color of the redaction using the fill argument on the page.addRedactAnnot() method, setting it to (0, 0, 0) will result in a black redaction. These are RGB values ranging from 0 to 1. For example, (1, 0, 0) will result in a red redaction, and so on.
def frame_matching_data(page, matched_values):
"""
frames matching values
"""
matches_found = 0
# Loop throughout matching values
for val in matched_values:
matches_found += 1
matching_val_area = page.searchFor(val)
for area in matching_val_area:
if isinstance(area, fitz.fitz.Rect):
# Draw a rectangle around matched values
annot = page.addRectAnnot(area)
# , fill = fitz.utils.getColor('black')
annot.setColors(stroke=fitz.utils.getColor('red'))
# If you want to remove matched data
#page.addFreetextAnnot(area, ' ')
annot.update()
return matches_foundThe frame_matching_data() function draws a red rectangle (frame) around the matching values.
Next, let's define a function to highlight text:
def highlight_matching_data(page, matched_values, type):
"""
Highlight matching values
"""
matches_found = 0
# Loop throughout matching values
for val in matched_values:
matches_found += 1
matching_val_area = page.searchFor(val)
# print("matching_val_area",matching_val_area)
highlight = None
if type == 'Highlight':
highlight = page.addHighlightAnnot(matching_val_area)
elif type == 'Squiggly':
highlight = page.addSquigglyAnnot(matching_val_area)
elif type == 'Underline':
highlight = page.addUnderlineAnnot(matching_val_area)
elif type == 'Strikeout':
highlight = page.addStrikeoutAnnot(matching_val_area)
else:
highlight = page.addHighlightAnnot(matching_val_area)
# To change the highlight colar
# highlight.setColors({"stroke":(0,0,1),"fill":(0.75,0.8,0.95) })
# highlight.setColors(stroke = fitz.utils.getColor('white'), fill = fitz.utils.getColor('red'))
# highlight.setColors(colors= fitz.utils.getColor('red'))
highlight.update()
return matches_foundThe above function applies the adequate highlighting mode on the matching values depending on the type of highlight inputted as a parameter.
You can always change the color of the highlight using the highlight.setColors() method as shown in the comments.
def process_data(input_file: str, output_file: str, search_str: str, pages: Tuple = None, action: str = 'Highlight'):
"""
Process the pages of the PDF File
"""
# Open the PDF
pdfDoc = fitz.open(input_file)
# Save the generated PDF to memory buffer
output_buffer = BytesIO()
total_matches = 0
# Iterate through pages
for pg in range(pdfDoc.pageCount):
# If required for specific pages
if pages:
if str(pg) not in pages:
continue
# Select the page
page = pdfDoc[pg]
# Get Matching Data
# Split page by lines
page_lines = page.getText("text").split('\n')
matched_values = search_for_text(page_lines, search_str)
if matched_values:
if action == 'Redact':
matches_found = redact_matching_data(page, matched_values)
elif action == 'Frame':
matches_found = frame_matching_data(page, matched_values)
elif action in ('Highlight', 'Squiggly', 'Underline', 'Strikeout'):
matches_found = highlight_matching_data(
page, matched_values, action)
else:
matches_found = highlight_matching_data(
page, matched_values, 'Highlight')
total_matches += matches_found
print(f"{total_matches} Match(es) Found of Search String {search_str} In Input File: {input_file}")
# Save to output
pdfDoc.save(output_buffer)
pdfDoc.close()
# Save the output buffer to the output file
with open(output_file, mode='wb') as f:
f.write(output_buffer.getbuffer())Related: How to Extract Text from PDF in Python
The main purpose of the process_data() function is the following:
- Open the input file.
- Create a memory buffer for storing temporarily the output file.
- Initialize a variable for storing the total number of matches of the string we were searching for.
- Iterate throughout the selected pages of the input file and split the current page into lines.
- Search for the string within the page.
- Apply the corresponding action (i.e
"Redact","Frame","Highlight", etc.) - Display a message signaling the status of the search process.
- Save and close the input file.
- Save the memory buffer to the output file.
It accepts several parameters:
input_file: The path of the PDF file to process.output_file: The path of the PDF file to generate after processing.search_str: The string to search for.pages: The pages to consider while processing the PDF file.action: The action to perform on the PDF file.
Get Our Practical Python PDF Processing EBook
Master PDF Manipulation with Python by building PDF tools from scratch. Get your copy now!
Download EBookNext, let's write a function to remove the highlight in case we want to:
def remove_highlght(input_file: str, output_file: str, pages: Tuple = None):
# Open the PDF
pdfDoc = fitz.open(input_file)
# Save the generated PDF to memory buffer
output_buffer = BytesIO()
# Initialize a counter for annotations
annot_found = 0
# Iterate through pages
for pg in range(pdfDoc.pageCount):
# If required for specific pages
if pages:
if str(pg) not in pages:
continue
# Select the page
page = pdfDoc[pg]
annot = page.firstAnnot
while annot:
annot_found += 1
page.deleteAnnot(annot)
annot = annot.next
if annot_found >= 0:
print(f"Annotation(s) Found In The Input File: {input_file}")
# Save to output
pdfDoc.save(output_buffer)
pdfDoc.close()
# Save the output buffer to the output file
with open(output_file, mode='wb') as f:
f.write(output_buffer.getbuffer())The purpose of the remove_highlight() function is to remove the highlights (not the redactions) from a PDF file. It performs the following:
- Open the input file.
- Create a memory buffer for storing temporarily the output file.
- Iterate throughout the pages of the input file and checks if annotations are found.
- Delete these annotations.
- Display a message signaling the status of this process.
- Close the input file.
- Save the memory buffer to the output file.
Now let's make a wrapper function that uses previous functions to call the appropriate function depending on the action:
def process_file(**kwargs):
"""
To process one single file
Redact, Frame, Highlight... one PDF File
Remove Highlights from a single PDF File
"""
input_file = kwargs.get('input_file')
output_file = kwargs.get('output_file')
if output_file is None:
output_file = input_file
search_str = kwargs.get('search_str')
pages = kwargs.get('pages')
# Redact, Frame, Highlight, Squiggly, Underline, Strikeout, Remove
action = kwargs.get('action')
if action == "Remove":
# Remove the Highlights except Redactions
remove_highlght(input_file=input_file,
output_file=output_file, pages=pages)
else:
process_data(input_file=input_file, output_file=output_file,
search_str=search_str, pages=pages, action=action)The action can be "Redact", "Frame", "Highlight", "Squiggly", "Underline", "Strikeout", and "Remove".
Let's define the same function but with folders that contain multiple PDF files:
def process_folder(**kwargs):
"""
Redact, Frame, Highlight... all PDF Files within a specified path
Remove Highlights from all PDF Files within a specified path
"""
input_folder = kwargs.get('input_folder')
search_str = kwargs.get('search_str')
# Run in recursive mode
recursive = kwargs.get('recursive')
#Redact, Frame, Highlight, Squiggly, Underline, Strikeout, Remove
action = kwargs.get('action')
pages = kwargs.get('pages')
# Loop though the files within the input folder.
for foldername, dirs, filenames in os.walk(input_folder):
for filename in filenames:
# Check if pdf file
if not filename.endswith('.pdf'):
continue
# PDF File found
inp_pdf_file = os.path.join(foldername, filename)
print("Processing file =", inp_pdf_file)
process_file(input_file=inp_pdf_file, output_file=None,
search_str=search_str, action=action, pages=pages)
if not recursive:
breakThis function is intended to process the PDF files included within a specific folder.
It loops throughout the files of the specified folder either recursively or not depending on the value of the parameter recursive and process these files one by one.
It accepts the following parameters:
input_folder: The path of the folder containing the PDF files to process.search_str: The text to search for in order to manipulate.recursive: whether to run this process recursively by looping across the subfolders or not.action: the action to perform among the list previously mentioned.pages: the pages to consider.
Before we make our main code, let's make a function for parsing command-line arguments:
def is_valid_path(path):
"""
Validates the path inputted and checks whether it is a file path or a folder path
"""
if not path:
raise ValueError(f"Invalid Path")
if os.path.isfile(path):
return path
elif os.path.isdir(path):
return path
else:
raise ValueError(f"Invalid Path {path}")
def parse_args():
"""Get user command line parameters"""
parser = argparse.ArgumentParser(description="Available Options")
parser.add_argument('-i', '--input_path', dest='input_path', type=is_valid_path,
required=True, help="Enter the path of the file or the folder to process")
parser.add_argument('-a', '--action', dest='action', choices=['Redact', 'Frame', 'Highlight', 'Squiggly', 'Underline', 'Strikeout', 'Remove'], type=str,
default='Highlight', help="Choose whether to Redact or to Frame or to Highlight or to Squiggly or to Underline or to Strikeout or to Remove")
parser.add_argument('-p', '--pages', dest='pages', type=tuple,
help="Enter the pages to consider e.g.: [2,4]")
action = parser.parse_known_args()[0].action
if action != 'Remove':
parser.add_argument('-s', '--search_str', dest='search_str' # lambda x: os.path.has_valid_dir_syntax(x)
, type=str, required=True, help="Enter a valid search string")
path = parser.parse_known_args()[0].input_path
if os.path.isfile(path):
parser.add_argument('-o', '--output_file', dest='output_file', type=str # lambda x: os.path.has_valid_dir_syntax(x)
, help="Enter a valid output file")
if os.path.isdir(path):
parser.add_argument('-r', '--recursive', dest='recursive', default=False, type=lambda x: (
str(x).lower() in ['true', '1', 'yes']), help="Process Recursively or Non-Recursively")
args = vars(parser.parse_args())
# To Display The Command Line Arguments
print("## Command Arguments #################################################")
print("\n".join("{}:{}".format(i, j) for i, j in args.items()))
print("######################################################################")
return argsFinally, let's write the main code:
if __name__ == '__main__':
# Parsing command line arguments entered by user
args = parse_args()
# If File Path
if os.path.isfile(args['input_path']):
# Extracting File Info
extract_info(input_file=args['input_path'])
# Process a file
process_file(
input_file=args['input_path'], output_file=args['output_file'],
search_str=args['search_str'] if 'search_str' in (args.keys()) else None,
pages=args['pages'], action=args['action']
)
# If Folder Path
elif os.path.isdir(args['input_path']):
# Process a folder
process_folder(
input_folder=args['input_path'],
search_str=args['search_str'] if 'search_str' in (args.keys()) else None,
action=args['action'], pages=args['pages'], recursive=args['recursive']
)Now let's test our program:
$ python pdf_highlighter.py --helpOutput:
usage: pdf_highlighter.py [-h] -i INPUT_PATH [-a {Redact,Frame,Highlight,Squiggly,Underline,Strikeout,Remove}] [-p PAGES]
Available Options
optional arguments:
-h, --help show this help message and exit
-i INPUT_PATH, --input_path INPUT_PATH
Enter the path of the file or the folder to process
-a {Redact,Frame,Highlight,Squiggly,Underline,Strikeout,Remove}, --action {Redact,Frame,Highlight,Squiggly,Underline,Strikeout,Remove}
Choose whether to Redact or to Frame or to Highlight or to Squiggly or to Underline or to Strikeout or to Remove
-p PAGES, --pages PAGES
Enter the pages to consider e.g.: [2,4]Before exploring our test scenarios, let me clarify few points:
- To avoid encountering the
PermissionError, please close the input PDF file before running this utility. - The input PDF file to process must not be a scanned PDF file.
- The search string complies with the rules of regular expressions using Python's built-in re module. For example, setting the search string to
"organi[sz]e"match both "organise" and "organize".
As a demonstration example, let’s highlight the word "BERT" in the BERT paper:
$ python pdf_highlighter.py -i bert-paper.pdf -a Highlight -s "BERT"Output:
## Command Arguments #################################################
input_path:bert-paper.pdf
action:Highlight
pages:None
search_str:BERT
output_file:None
######################################################################
## File Information ##################################################
File:bert-paper.pdf
Encrypted:False
format:PDF 1.5
title:
author:
subject:
keywords:
creator:LaTeX with hyperref package
producer:pdfTeX-1.40.17
creationDate:D:20190528000751Z
modDate:D:20190528000751Z
trapped:
encryption:None
######################################################################
121 Match(es) Found of Search String BERT In Input File: bert-paper.pdfAs you can see, 121 matches were highlighted, you can use other highlighting options, such as underline, frame, and others. Here is the resulting PDF:
 Let's remove it now:
Let's remove it now:
$ python pdf_highlighter.py -i bert-paper.pdf -a RemoveThe resulting PDF will remove the highlighting.
Conclusion
I invite you to play around with other actions, as I find it quite interesting to do it automatically with Python.
If you want to highlight text from multiple PDF files, you can either specify the folder to the -i parameter or merge the pdf files together and run the code to come up with a single PDF that has all the text you want to be highlighted.
I hope you enjoyed this article and found it interesting. Check the full code here.
Other related handling PDF tutorials:
- How to Watermark PDF Files in Python.
- How to Extract Images from PDF in Python.
- How to Extract All PDF Links in Python.
- How to Extract Tables from PDF in Python.
- How to Convert PDF to Images in Python.
For more PDF handling guides on Python, you can check our Practical Python PDF Processing EBook, where we dive deeper into PDF document manipulation with Python, make sure to check it out here if you're interested!
Happy coding ♥
Let our Code Converter simplify your multi-language projects. It's like having a coding translator at your fingertips. Don't miss out!
View Full Code Convert My Code



Got a coding query or need some guidance before you comment? Check out this Python Code Assistant for expert advice and handy tips. It's like having a coding tutor right in your fingertips!